Why Your Iceberg Tables Are 3-10× More Expensive to Store Than They Should Be
The modern data lakehouse architecture promises a seductive "Goldilocks" zone: the elastic, low-cost storage of an S3 bucket paired with the ACID guarantees and performance of a traditional data warehouse. Apache Iceberg has emerged as the de facto standard for this layer, providing the metadata abstraction necessary for schema evolution, hidden partitioning, and time travel.
However, many platform teams find that the transition from a "Hive-style" mess to an Iceberg lakehouse doesn't automatically lower the TCO. Instead, they encounter a Storage-Performance Paradox: as ingestion frequency increases (moving toward real-time), query performance degrades and cloud bills spike.
To solve this, we must look past the table format and into the mechanics of the Iceberg metadata hierarchy-and why the traditional imperative approach to table maintenance is a scaling dead-end.
The Technical Roots of "Iceberg Bloat"
To optimize Iceberg, you must understand that it is essentially a distributed B-tree for object storage. Every write operation produces an immutable trail of metadata. While this enables "Time Travel," it creates three primary technical debt vectors:
1. The Metadata Read-Amplification
Iceberg performs "Manifest Pruning" to skip irrelevant data files. However, if you have a high-frequency streaming ingest (e.g., Flink or Spark Streaming committing every 2 minutes), you generate a massive volume of Manifest Files.
- The Technical Hit: During query planning, the engine must scan the Manifest List to find relevant Manifest Files. If these metadata files are fragmented into thousands of tiny objects, the query coordinator spends more time performing S3
GETrequests for metadata than actually processing data.
2. Delete Vector Tax (Merge-on-Read)
Iceberg V3 tables support row-level deletes using Merge-on-Read (MoR). This avoids rewriting whole 128MB Parquet files for a single row change by writing a "Delete File" instead.
- The Technical Hit: These deletes are applied at read-time. If you have a high churn of updates, the query engine must perform a "Hash Join" or "Merge" between the base data files and a mountain of tiny Position or Equality Delete files. Without compaction, your vCPU usage scales linearly with the number of unmerged deletes, not the volume of data.
3. Orphaned Data & Snapshot Retention
Every COMMIT in Iceberg creates a new Snapshot. Even if you "delete" data, the physical files remain in S3 to support VERSION AS OF queries.
- The Technical Hit: Without a proactive
expireSnapshotsandremoveOrphanFilesstrategy, your storage costs will grow monotonically, regardless of your actual "live" data size. In CDC (Change Data Capture) workloads, the storage footprint can easily be 5x-10x the logical table size within weeks.
Why "Imperative" Maintenance is a Trap
The standard industry response to these issues is Imperative Maintenance. This involves writing manual Spark SQL maintenance scripts or Airflow DAGs:
-- The Manual (Imperative) Approach
CALL system.rewrite_data_files(table => 'prod.events', strategy => 'sort', ...);
CALL system.rewrite_manifests(table => 'prod.events');
CALL system.expire_snapshots(table => 'prod.events', retain_last => 100);
This approach is fundamentally flawed for three reasons:
- Resource Contention: Maintenance jobs often "fight" with production ETL for cluster resources, leading to OOM (Out of Memory) errors or SLA breaches.
- State Ignorance: Imperative scripts run on a schedule (Cron), not based on the actual state of the table. You might compact a table that doesn't need it, wasting compute, or leave a hot table fragmented for 23 hours.
- The "Toil" Ceiling: As your Lakehouse grows from 10 tables to 1,000, managing the individual maintenance logic for every schema becomes a full-time job for a Data Engineer.
The Declarative Shift: Table-State-as-Code
In modern infrastructure, we moved from imperative shell scripts to Declarative Orchestration (like Kubernetes). We define a "Desired State" (e.g., I want 3 replicas of this app) and a controller reconciles the reality to match it.
The same logic must apply to the Data Lakehouse. A Declarative Data Platform doesn't ask the engineer to "run a compaction job." Instead, the engineer declares the Table Policy:
- Target Data File Size: 128MB
- Retention Policy: 7 Days
- Optimization Strategy: Z-Order on
customer_id
The platform's Reconciliation Loop then monitors metadata statistics in real-time. When the "Small File Count" or "Delete File Ratio" exceeds a threshold, the platform triggers background optimization tasks automatically.
Auto-Optimization in Dataverses
At Dataverses, we've built this declarative intelligence directly into the core of our streaming data platform. We treat Iceberg table health as a managed service, not an operational burden.
How Dataverses Reconciles Your Lakehouse:
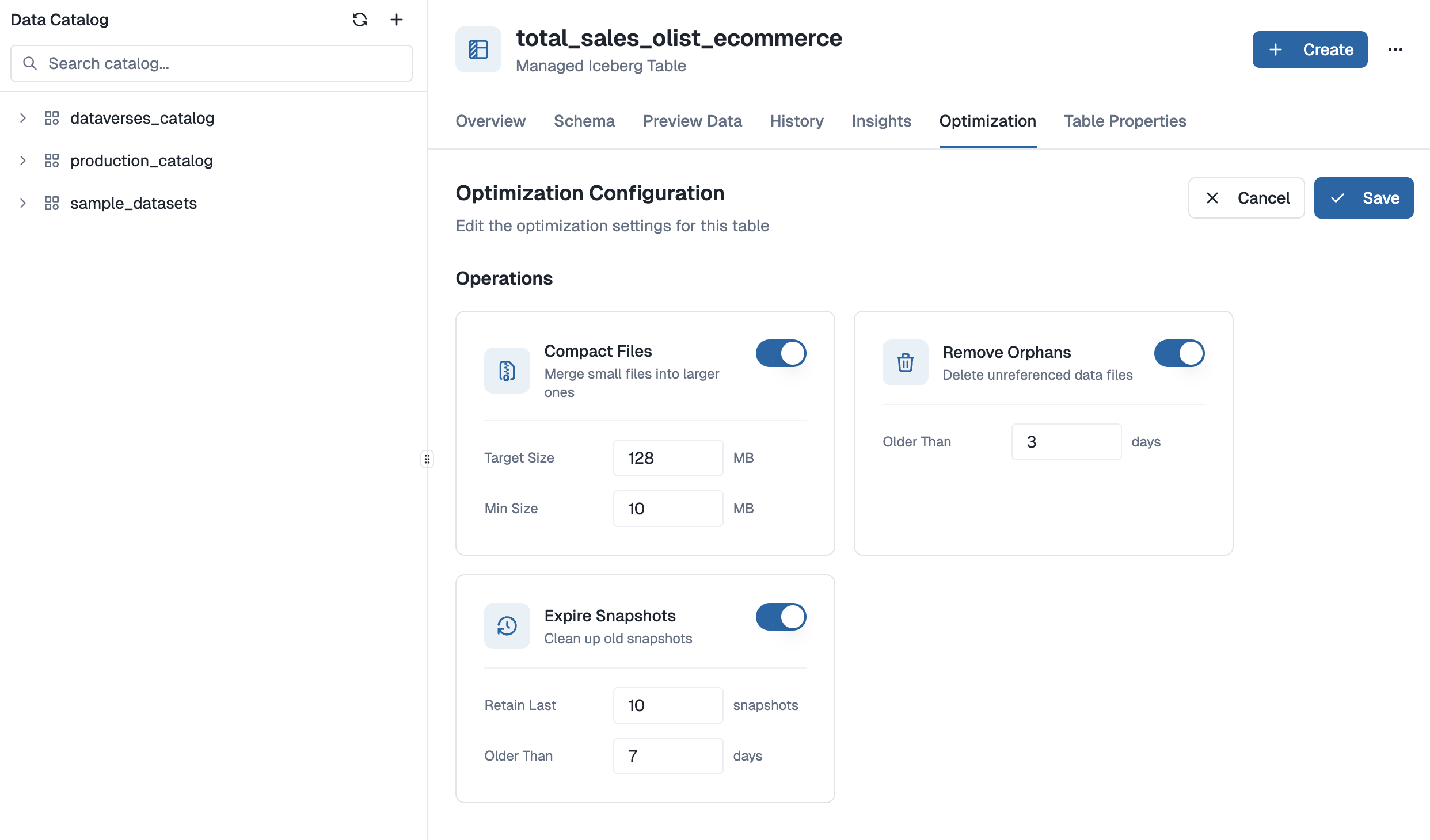
The Dataverses platform provides an intuitive UI to configure all three optimization operations:
- Background Compaction (Zero-Interruption): Configure target file size (default 128MB) and minimum file size (default 10MB). Our engine monitors manifest clusters and automatically performs "Bin-Packing" or "Sort" rewrites in the background without locking the table or interrupting active writers.
- Intelligent Snapshot Lifecycle: Set retention policies (e.g., retain last 10 snapshots, expire older than 7 days). We automate the
expireSnapshotsprocess based on your specific compliance and recovery windows, ensuring that "Ghost Data" is purged from S3 immediately upon expiration. - Automated Delete-File Merging: For CDC and transactional workloads, Dataverses detects high "Delete Vector" density and preemptively merges them into the base Parquet files, keeping your Read-Amplification near zero.
- Metadata Pruning: We regularly rewrite Manifest Lists to ensure query planning stays sub-second, even for tables with petabytes of historical data.
Conclusion: Focus on Data, Not Files
The promise of the Lakehouse is agility. If your Data Engineers are spending 30% of their sprint cycles tuning Spark parameters for compaction jobs, you haven't actually built a modern platform-you've just moved your technical debt to a different folder.
By moving to a declarative optimization model, you decouple business logic from storage mechanics. With Dataverses, your Iceberg tables remain perpetually "clean," ensuring that your cloud bill stays predictable and your queries stay fast-automatically.
Stop managing files. Start managing data. Ready to see how Dataverses can optimize your Iceberg footprint? Explore our platform today.
Tags
Keep up with us
Get the latest updates on data engineering and AI delivered to your inbox.
Contents in this story
Recommended for you

Code Smarter, Not Harder: Meet the New Notebook Code Generation on Dataverses
May 23, 2026 · 4 min read

Apache Iceberg 1.11.0 Release: Deletion Vectors, Variant Type, and V3 Maturity
May 22, 2026 · 7 min read

Spark Declarative Pipelines in Apache Spark 4.1: A Complete Guide
May 1, 2026 · 7 min read
