Tại sao bảng Iceberg của bạn tốn lưu trữ gấp 3–10× so với mức cần thiết
Kiến trúc data lakehouse hiện đại hứa hẹn vùng "vừa phải": lưu trữ đàn hồi, chi phí thấp của bucket S3 kết hợp với đảm bảo ACID và hiệu năng của data warehouse truyền thống. Apache Iceberg đã trở thành chuẩn thực tế cho lớp này, cung cấp abstraction metadata cần thiết cho schema evolution, hidden partitioning và time travel.
Tuy nhiên, nhiều đội nền tảng thấy việc chuyển từ "đống kiểu Hive" sang lakehouse Iceberg không tự động giảm TCO. Thay vào đó, họ gặp Nghịch lý Lưu trữ–Hiệu năng: khi tần suất ingestion tăng (tiến tới thời gian thực), hiệu năng truy vấn giảm và hóa đơn đám mây tăng vọt.
Để giải quyết, chúng ta phải nhìn qua định dạng bảng vào cơ chế của hệ thống phân cấp metadata Iceberg—và tại sao cách tiếp cận imperative truyền thống cho bảo trì bảng là ngõ cụt khi scale.
Nguồn gốc kỹ thuật của "Iceberg Bloat"
Để tối ưu Iceberg, bạn cần hiểu nó về bản chất là B-tree phân tán cho object storage. Mỗi thao tác ghi tạo ra một chuỗi metadata bất biến. Trong khi điều này cho phép "Time Travel", nó tạo ra ba vector nợ kỹ thuật chính:
1. Metadata Read-Amplification
Iceberg thực hiện "Manifest Pruning" để bỏ qua file dữ liệu không liên quan. Tuy nhiên, nếu bạn có ingestion streaming tần suất cao (ví dụ Flink hoặc Spark Streaming commit mỗi 2 phút), bạn tạo ra khối lượng lớn Manifest Files.
- Tác động kỹ thuật: Trong giai đoạn lập kế hoạch truy vấn, engine phải quét Manifest List để tìm Manifest Files liên quan. Nếu các file metadata này bị phân mảnh thành hàng nghìn object nhỏ, query coordinator dành nhiều thời gian thực hiện request S3
GETcho metadata hơn là xử lý dữ liệu thực sự.
2. Delete Vector Tax (Merge-on-Read)
Bảng Iceberg V3 hỗ trợ xóa cấp dòng bằng Merge-on-Read (MoR). Cách này tránh ghi lại toàn bộ file Parquet 128MB cho một thay đổi dòng bằng cách ghi "Delete File" thay thế.
- Tác động kỹ thuật: Các delete được áp dụng lúc đọc. Nếu bạn có nhiều cập nhật, engine truy vấn phải thực hiện "Hash Join" hoặc "Merge" giữa file dữ liệu gốc và hàng đống file Position hoặc Equality Delete nhỏ. Không compact, mức dùng vCPU scale tuyến tính với số delete chưa merge, không phải khối lượng dữ liệu.
3. Dữ liệu mồ côi & Snapshot Retention
Mỗi COMMIT trong Iceberg tạo Snapshot mới. Dù bạn "xóa" dữ liệu, file vật lý vẫn nằm trên S3 để hỗ trợ truy vấn VERSION AS OF.
- Tác động kỹ thuật: Không có chiến lược chủ động
expireSnapshotsvàremoveOrphanFiles, chi phí lưu trữ sẽ tăng đơn điệu, bất kể kích thước dữ liệu "sống" thực tế. Trong workload CDC, footprint lưu trữ có thể dễ dàng gấp 5–10× kích thước bảng logic trong vài tuần.
Tại sao bảo trì "Imperative" là bẫy
Phản ứng chuẩn của ngành với các vấn đề này là Bảo trì Imperative. Điều này gồm viết script bảo trì Spark SQL thủ công hoặc Airflow DAG:
-- Cách thủ công (Imperative)
CALL system.rewrite_data_files(table => 'prod.events', strategy => 'sort', ...);
CALL system.rewrite_manifests(table => 'prod.events');
CALL system.expire_snapshots(table => 'prod.events', retain_last => 100);
Cách tiếp cận này về cơ bản sai vì ba lý do:
- Tranh chấp tài nguyên: Job bảo trì thường "đụng độ" với ETL production cho tài nguyên cluster, dẫn đến OOM hoặc vi phạm SLA.
- Không biết trạng thái: Script imperative chạy theo lịch (Cron), không dựa trên trạng thái thực của bảng. Bạn có thể compact bảng không cần, lãng phí compute, hoặc để bảng nóng phân mảnh suốt 23 giờ.
- Trần "Toil": Khi Lakehouse của bạn từ 10 bảng lên 1.000, quản lý logic bảo trì riêng cho từng schema trở thành công việc toàn thời gian cho Data Engineer.
Chuyển dịch khai báo: Table-State-as-Code
Trong hạ tầng hiện đại, chúng ta chuyển từ script shell imperative sang Orchestration khai báo (như Kubernetes). Chúng ta định nghĩa "Desired State" (ví dụ tôi muốn 3 replica của app này) và controller hòa giải thực tế để khớp.
Logic tương tự phải áp dụng cho Data Lakehouse. Nền tảng dữ liệu khai báo không yêu cầu kỹ sư "chạy job compaction". Thay vào đó, kỹ sư khai báo Table Policy:
- Kích thước file dữ liệu mục tiêu: 128MB
- Chính sách retention: 7 ngày
- Chiến lược tối ưu: Z-Order trên
customer_id
Reconciliation Loop của nền tảng sau đó giám sát thống kê metadata theo thời gian thực. Khi "Small File Count" hoặc "Delete File Ratio" vượt ngưỡng, nền tảng kích hoạt tác vụ tối ưu nền tự động.
Auto-Optimization trong Dataverses
Tại Dataverses, chúng tôi đã xây trí tuệ khai báo này trực tiếp vào lõi nền tảng dữ liệu streaming. Chúng tôi coi sức khỏe bảng Iceberg là dịch vụ managed, không phải gánh vận hành.
Cách Dataverses hòa giải Lakehouse của bạn:
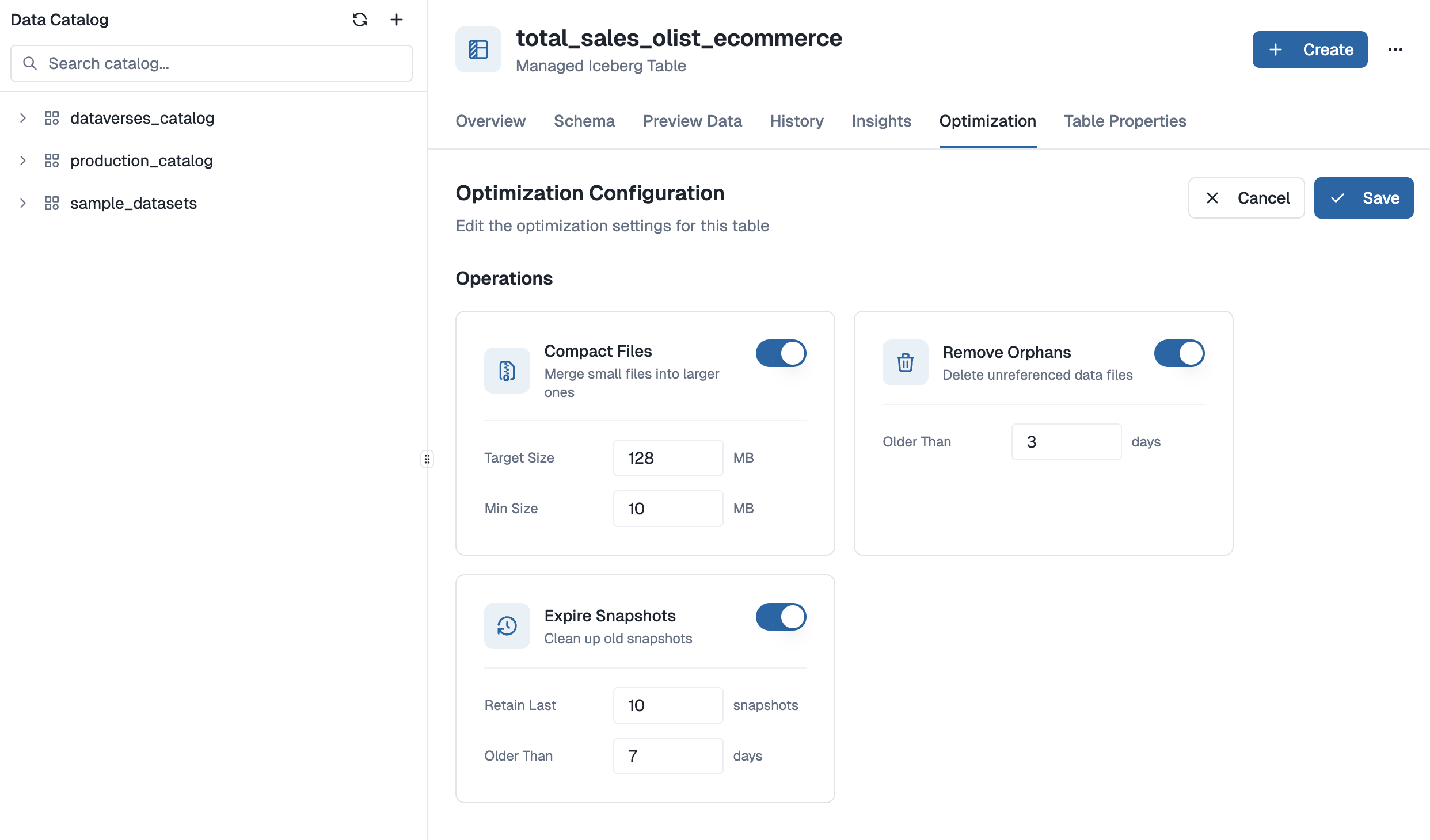
Nền tảng Dataverses cung cấp UI trực quan để cấu hình cả ba thao tác tối ưu:
- Background Compaction (không gián đoạn): Cấu hình kích thước file mục tiêu (mặc định 128MB) và kích thước file tối thiểu (mặc định 10MB). Engine giám sát cluster manifest và tự thực hiện rewrite "Bin-Packing" hoặc "Sort" ở nền mà không khóa bảng hay làm gián đoạn writer đang hoạt động.
- Intelligent Snapshot Lifecycle: Đặt chính sách retention (ví dụ giữ 10 snapshot cuối, expire cũ hơn 7 ngày). Chúng tôi tự động hóa quy trình
expireSnapshotstheo cửa sổ tuân thủ và phục hồi cụ thể của bạn. - Automated Delete-File Merging: Cho workload CDC và giao dịch, Dataverses phát hiện mật độ "Delete Vector" cao và chủ động merge vào file Parquet gốc, giữ Read-Amplification gần không.
- Metadata Pruning: Chúng tôi thường xuyên rewrite Manifest List để đảm bảo lập kế hoạch truy vấn dưới một giây, kể cả với bảng có petabyte dữ liệu lịch sử.
Kết luận: Tập trung vào dữ liệu, không phải file
Lời hứa của Lakehouse là sự linh hoạt. Nếu Data Engineer của bạn dành 30% chu kỳ sprint chỉnh tham số Spark cho job compaction, bạn chưa thực sự xây nền tảng hiện đại—bạn chỉ chuyển nợ kỹ thuật sang thư mục khác.
Bằng cách chuyển sang mô hình tối ưu khai báo, bạn tách logic nghiệp vụ khỏi cơ chế lưu trữ. Với Dataverses, bảng Iceberg của bạn luôn "sạch", đảm bảo hóa đơn đám mây dự đoán được và truy vấn luôn nhanh—tự động.
Ngừng quản lý file. Bắt đầu quản lý dữ liệu. Sẵn sàng xem Dataverses tối ưu footprint Iceberg của bạn thế nào? Khám phá nền tảng ngay hôm nay.
Thẻ
Cập nhật cùng chúng tôi
Nhận những cập nhật mới nhất về kỹ thuật dữ liệu và AI gửi đến hộp thư của bạn.
Nội dung bài viết
Gợi ý cho bạn

Phát hiện gian lận trong tài chính: Cách Dataverses biến dữ liệu thành tuyến phòng thủ đầu tiên của bạn
28 thg 2, 2026 · 8 phút đọc

Tại sao Dataverses mang lại hiệu quả chi phí vượt trội so với BigQuery và Redshift: Phân tích kiến trúc và kinh tế sâu
25 thg 2, 2026 · 7 phút đọc

Xây dựng Doanh nghiệp Thông minh: Kiến trúc Data Lakehouse của Dataverses
20 thg 2, 2026 · 2 phút đọc
